Data Orchestration Ecosystem





Abstract
In this article today, we’re exploring how we streamlined data pipeline management with a configurable, low code/no code Data Orchestration Ecosystem (DOE), enabling seamless data ingestion, transformation, and enrichment. Built on Prefect, Kubernetes, and Azure, DOE accelerates insights extraction, enhances data quality, and optimizes operational efficiency.
About Our Client
Our client is a cutting-edge artificial intelligence company that focuses on providing AI-powered solutions for various industries, including aerospace, defense, energy, utilities, manufacturing, finance, telecommunications, and more. Their primary requirement was to build efficient configurable/Low Code data pipelines that could seamlessly integrate various data sources.

Solution Details
The Data Orchestration Ecosystem (DOE), built upon Prefect, enables seamless data ingestion, transformation, and enrichment through a user-friendly interface requiring minimal coding. Its versatility and scalability make it adaptable to diverse requirements, allowing for effortless customization.
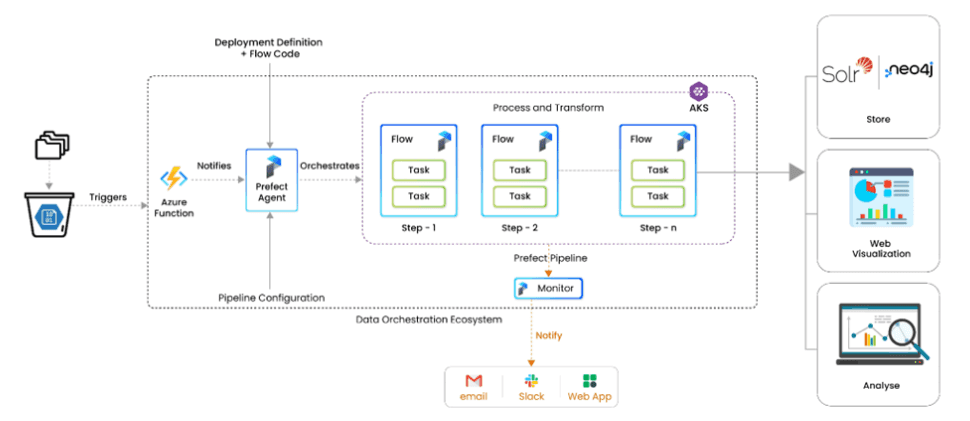
Below are the details of the major components of the DOE.
Automates processes by executing tasks on a schedule or in response to real-time events. Uses Azure Function Apps to trigger pipeline execution, eliminating infrastructure management.
Defines, schedules, and monitors workflows with built-in retries and distributed execution. Ensures seamless orchestration with logging and version control.
Enhances scalability and flexibility by managing containerized data workflows. Automates deployment, scaling, and execution for efficient processing.
A React-based front end with a FastAPI REST server allows users to configure data pipelines easily. Enables visualization, filtering, and searching for seamless data exploration.
Users configure pipelines, Azure functions trigger execution, Prefect loads configurations, and Kubernetes runs workflows. Processed data is stored in graph for analysis.

Technology Used










Significantly reduces the time needed to extract insights from data by simply updating the pipeline configuration, improving the speed of decision-making.
Enhances data quality by effectively cleaning and correcting errors, leading to more reliable insights and better decisions.
By automating data processing tasks, it boosts operational efficiency, allowing data experts to focus on innovation and development.
Contributes to cost savings by automating tasks and improving data quality, resulting in reduced expenses for data management.
Conclusion
Building scalable and configurable data pipelines presents unique challenges, but with the right architecture, it becomes a seamless process. By leveraging event driven automation, distributed workflow management, and containerized execution, our solution ensures efficiency, scalability, and real time processing. With an intuitive interface and advanced visualization capabilities, businesses can easily manage data workflows, extract meaningful insights, and adapt to evolving needs.






What Our Customers Say
Real experiences, real impact. See how we've helped customers thrive with tailored services.



Tech Prescient was very easy to work with and was always proactive in their response.
The team was technically capable, well rounded, nimble and agile. They could interpret, adopt and implement the required changes quickly.

MURALI RAMSUNDER
SENIOR ARCHITECT, VONAGE.COM


Amit and his team at Tech Prescient have been a fantastic partner to Measured.
We have been working with Tech Prescient for over three years now and they have aligned to our in-house India development efforts in a complementary way to accelerate our product road map.

TREVOR TESTWUIDE
CO-FOUNDER & CEO, MEASURED INC.

We were lucky to have Amit and his team at Tech Prescient build CeeTOC platform from grounds-up.
Having worked with several other services companies in the past, the difference was stark and evident.

ALOK SRIVASTAVA, PHD
FOUNDER AND CEO, CEETOC INC.

We have been extremely fortunate to work closely with Amit and his team at Tech Prescient.
The team will do whatever it takes to get the job done and still deliver a solid product with utmost attention to details.

SREENIVASA GORTI, PHD
CTO / CO-FOUNDER, INNOSTREAMS INC.
Customer success stories