


Mastering Time-Series Data: Scalable Solutions with TimescaleDB






Abstract
Effectively managing time-series data is crucial for applications that monitor changes over time, such as IoT devices, financial markets, and system performance metrics. TimescaleDB, an open-source time-series database extension for PostgreSQL, offers robust solutions tailored for these workloads. This article explores the nature of time-series data, introduces TimescaleDB, and outlines a structured approach to managing time-series data using TimescaleDB, including best practices and implementation steps.
Background and Problem Statement
Efficient Querying
Data Retention
Storage Challenges
Performance Challenges
Solution Details
Time Series Data: An Overview
Time-series data represents how a system, process, or behavior changes over time. For example, if you are taking measurements from a temperature gauge every five minutes, you are collecting time-series data. Another common example is stock price changes or even the battery life of your smartphone. As these measurements change over time, each data point is recorded alongside its timestamp, allowing it to be measured, analyzed, and visualized.
While databases have always had time fields, specialized databases for handling time series data can make your database work more effectively. Examples of various time-series databases are TimescaleDB, InfluxDB, and Prometheus.
-
TimescaleDB: TimescaleDB is an extension for PostgreSQL that enables time-series workloads, increasing ingest, query, storage, and analytics performance. This characteristic of being built on top of PostgreSQL is one of its key differentiating factors from other time series databases. It allows you to use the familiarity of battle-tested PostgreSQL features like SQL with its query optimizer (as opposed to another domain-specific language like flux in InfluxDB), replication, and interoperability with other PostgreSQL extensions.
-
Hypertables: Hypertables are a TimescaleDB feature which are PostgreSQL tables that automatically partition your data by time. You interact with hypertables in the same way as regular PostgreSQL tables, but with extra features that make managing your time-series data much easier. When you create and use a hypertable, it automatically partitions data by time, and optionally by space.
Implementation Steps
Efficient Querying
Queries on time-series data typically range between two types: time-bound queries and time-series analysis queries.
-
Time-Bound Queries: TimescaleDB enhances query performance through time based partitioning and native indexing strategies B-tree indexes that speed up time-bound queries. Queries automatically target relevant chunks, eliminating unnecessary data scans.
-
Time-Series Analysis Queries: Continuous Aggregates automatically materialize frequently run aggregate queries, updating incrementally with new data. This dramatically improves the performance of analytical workloads by avoiding repeated full-table scans and reducing query latency.
Data Retention
Time-Series data often requires different retention policies based on the data's age and importance. For example, data for the current day may be required for real-time analysis, while data for the previous month/year may be used for trend analysis and data older than 6 months may not be required at all.
- Compression: TimescaleDB introduces native compression that converts historical data into a highly efficient columnar storage format, reducing disk usage. This compression is optimized for aggregated queries on older data. For example, The below query sets up a compression policy to compress data older than 1 month.
SELECT add_compression_policy('conditions', older_than => INTERVAL '1 month');
- Data Retention Policies: TimescaleDB supports data retention policies which run a process periodically to remove old data based on the retention policy defined. For example, The below query sets up a retention policy to delete data older than 6 months.
SELECT add_retention_policy('conditions', drop_after => INTERVAL '6 months');
Storage Challenges
Time-Series data can grow exponentially, leading to storage challenges. Also, different tables may have different I/O requirements and the same strategy may not be applicable across the board.
-
Horizontally scaling storage within a single node: TimescaleDB supports tablespaces, enabling fine-grained control over data placement across multiple storage devices. This feature let's us attach multiple volumes instead of increasing the size of an existing volume.
-
Tiered Storage: Using tablespaces also allows critical data to reside on high-performance SSDs (e.g., AWS io1/io2 volumes) while less frequently accessed data can be stored on cost-effective general-purpose storage (e.g., AWS gp3 volumes).
Performance challenges
Besides all the strategies mentioned above, there are still many performance challenges that can be addressed.
-
Performance Tuning: TimescaleDB provides a set of configuration parameters that can be tuned to optimize performance based on the workload. We can also use timescaledb-tune, an open source tool developed by Timescale which can automatically apply some common parameters to postgres, ideal for time-series data.
-
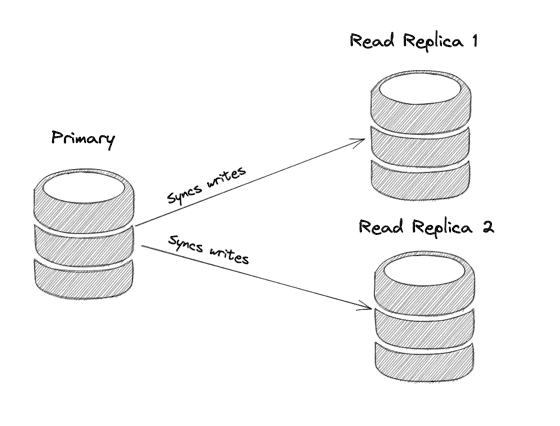
Replication: TimescaleDB supports replication, which can be used to scale out read queries and improve fault tolerance. Replication involves copying data from one database server (the primary) to another (the replica). This can be particularly useful for distributing read loads and ensuring high availability. TimescaleDB leverages PostgreSQL's built-in streaming replication. In this setup, the primary server continuously streams WAL (Write-Ahead Logging) records to the replica servers. This ensures that the replicas are nearly up-to-date with the primary server, allowing for efficient read scaling and quick failover in case of primary server failure.
-
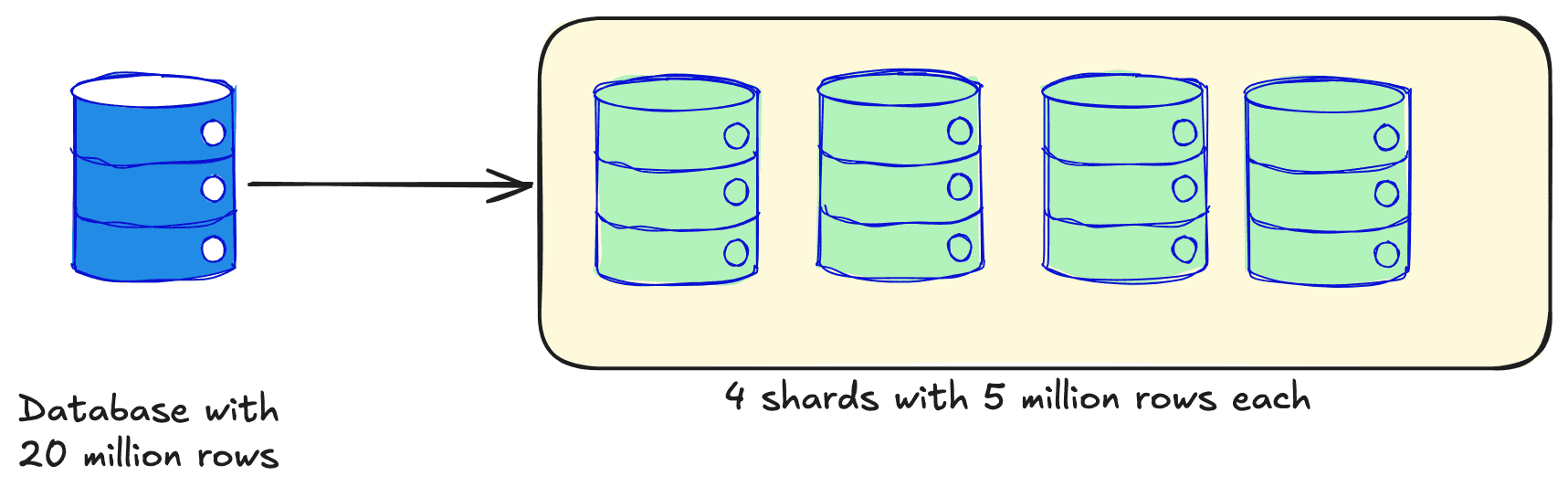
Sharding: Sharding is a technique used to horizontally partition data across multiple servers. TimescaleDB does not natively support sharding as they have deprecated Multi-node distributed hypertables. However, it is still possible to setup application level sharding. This approach should be considered only when the previously mentioned approaches still do not meet the performance requirements.
Technology Used


Best Practices and Recommendations

Analyze the existing/potential usage patterns and select the appropriate time column for partitioning and indexing to optimize query performance.
Enable native compression to reduce storage costs and improve query performance for historical data.
Materialize frequently run aggregate queries using continuous aggregates to improve query performance and reduce latency.
Optimize TimescaleDB and Postgres configuration parameters based on workload requirements to improve query performance and resource utilization. Start with timescaledb-tune and then fine-tune it based on your requirements.
Conclusion
Effectively managing time-series data is essential for modern applications that demand high performance, scalability, and cost-efficiency. TimescaleDB, with its PostgreSQL foundation, offers a powerful solution tailored for time-series workloads. Its features—such as hypertables for seamless partitioning, continuous aggregates for accelerated queries, native compression and retention policies for efficient data lifecycle management, and advanced storage and scalability options—empower organizations to handle vast amounts of data with ease.
References and Further Reading
- https://docs.timescale.com/getting-started/latest/time-series-data/
- https://docs.timescale.com/use-timescale/latest/hypertables/about-hypertables/
- https://docs.timescale.com/self-hosted/latest/configuration/timescaledb-tune/






Blogs You Might Like




