Non-Human Identity Security: What It Is and Why It Matters


Non-human identities (NHIs) are digital credentials that embody machines, applications, and automated processes in IT infrastructure, primarily enabling them to authenticate and consume resources on their own, with no human assistance. While human identities are generally connected to individual users, NHIs enable machine-to-machine interaction and are designed to complete repetitive tasks across cloud-native and on-premises environments autonomously. This includes service accounts, API keys, OAuth tokens, certificates, and workload identities that are the backbone of the automated workflows that enterprises count on today. When your payment application connects to the database at 3 AM, when CI/CD pipelines push code to production, or when microservices in Kubernetes talk thousands of times per second, NHIs are managing and automating complex interactions.
Gartner research shows that in a typical cloud environment, NHIs outnumber human identities 45:1. For every employee account that is typically formally managed through an HR process, there are 45 service accounts, API keys, and certificates with minimal to no oversight.
This causes major issues. When security incidents occur, it is because service accounts are using systems without enterprise inventory. When a compliance audit occurs, the organization cannot provide records authorizing which service accounts have access to financial data. When SOX or HIPAA reviews occur, compliance officers realize that service accounts do not receive access certifications every quarter.
For CISOs, IT directors, compliance officers, and HRIS leads, deciphering non-human identity security represents a significant capability gap that needs to be addressed immediately.
Key Takeaways:
- What NHIs are and how they differ from human identities in authentication, lifecycle, and ownership
- Types of NHIs: API keys, service accounts, certificates, SSH keys, cloud workload identities, and RPA bots
- Major security risks: over-privileged accounts (42% have admin rights), hardcoded secrets (10M+ exposed annually), lifecycle gaps (68% can't inventory accounts), and shadow identities
- Best practices: complete discovery, least privilege enforcement, automated rotation, centralized secrets management, continuous monitoring, and Zero Trust principles
- NHIM explained how Non-Human Identity Management extends IAM to machine credentials for SOX, HIPAA, and GDPR compliance
- Future trends: ephemeral workload identities in Kubernetes/serverless, AI-driven anomaly detection, and CIEM integration
What Are Non-Human Identities?
A non-human identity, or NHI, is a digital entity that facilitates machine-to-machine access and authentication within software ecosystems. NHIs are ascribed to applications, bots, devices, or workloads, enabling them to log in and act in an automated fashion without a human supervising each action. When a human uses or accesses the software system, they decide to log in. NHIs rely upon programmatic logic whereby the application code determines when and how to access resources automatically.
Access is granted to NHIs through various forms of authentication, including secrets (access keys, passwords), certificates (digital certificates for TLS/SSL), and tokens (OAuth tokens, bearer tokens). One example of an NHI is an application with a service account that authenticates to a cloud-based application such as AWS or Azure. The application utilizes secrets, certificates, or tokens to authenticate as a service account defined at the time the service account was created and granted permissions. Another example could be using an API key to connect to third-party software such as Stripe or Twilio to perform operations. The NHI applications, or bots, access data and perform actions based on what was requested or permitted to be done by the assigned service account and role/permissions.
With NHIs, here is where things can become problematic; the access that is granted for NHIs is usually defined only by the required interactions and typically is more permissive than what human users are required to work under or under the permissions/horizon.
Why is that? NHIs need to work independently and continuously, operating on 24/7 conditions, and require no human approval to frequently move forward. This higher freedom of operation raises security concerns when not properly governed.
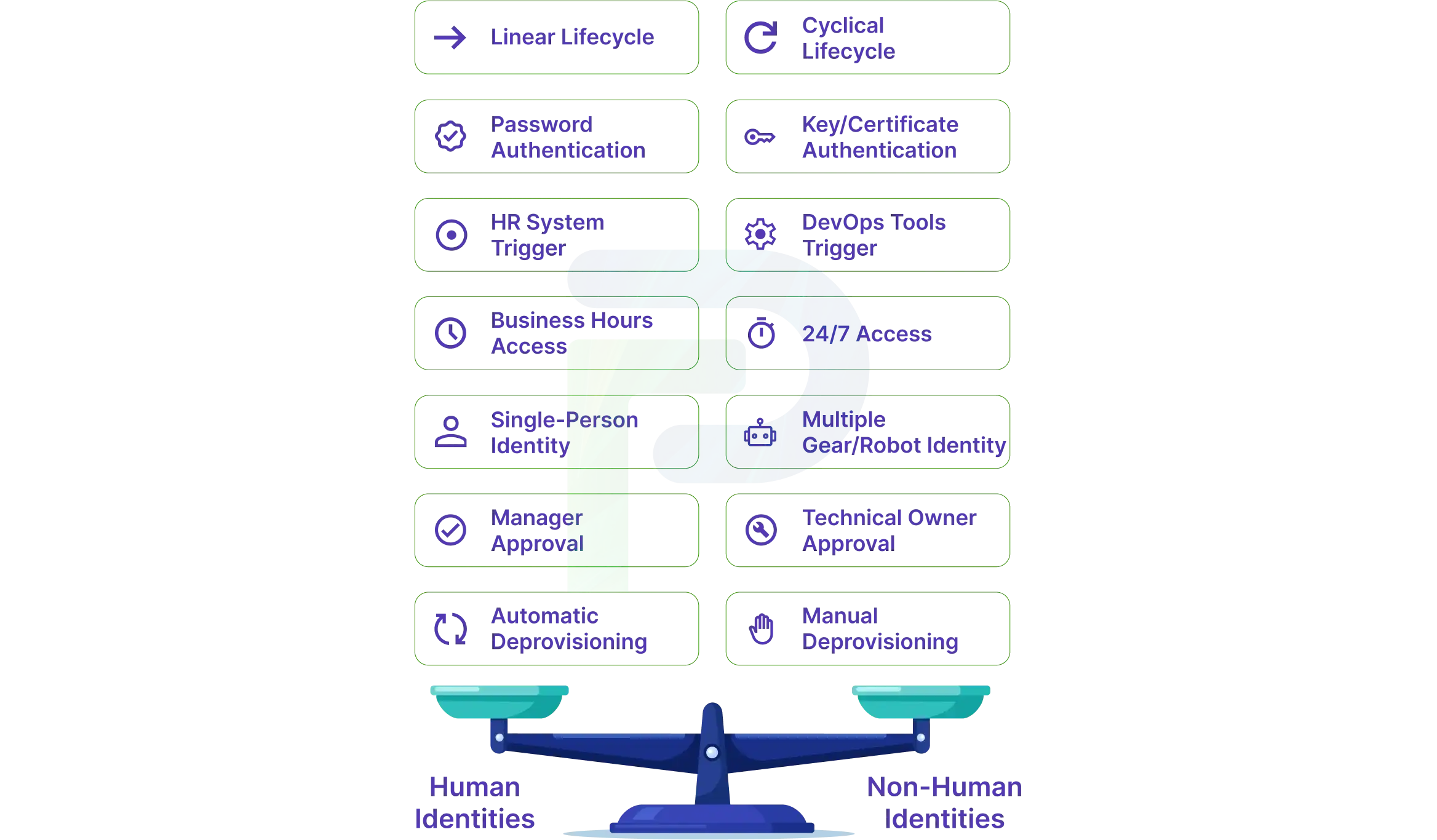
How Non-Human Identities Differ from Human Identities
Grasping the core aspects of different types of identities for humans and machines is a key consideration for effectively governing identity. Human identities, whose creation is intentional (through HR processes) and assigned to a specific individual, are quite different than those that we consider non-human identities, whose creation is based on machine-to-machine processes in a highly iterative and automated way as an application is deployed and infrastructure provisioned.
Human identities in the context of Identity and Access Management (IAM) refer to identifiers like usernames and associated personal attributes assigned to a human being. This all relates to the administration of 'security controls' that track user actions, establish permissioning models based on a set of users' roles, and establish personal accountability for the actions they take in a system or systems.
'Non-human', 'service account system' or 'machine identity' refers to an actor that is not human but would instead be thought of as or authenticate as a credential that would be used for apps or applications to talk to one another to perform a task. The management of these types of identities is critical because they manage communication securely with other apps or systems and human developers and provide system-level accountability to the system processes that take place at the application layer.
The major differentiation should be conceptually simple: human identities are tied to human users and their human attributes (or personal attributes), i.e., name, department, job role, manager, etc.; non-human identities are tied, as the name implies, are associated with systems or applications whose function is not connected to personal attributes or individual behaviour.
| Aspect | Human Identities | Non-Human Identities |
|---|---|---|
| Lifecycle Trigger | HR events (hire/terminate) | Application deployment/retirement |
| Authentication | Password + MFA, biometrics | API keys, certificates, tokens |
| Access Pattern | Business hours, intermittent | 24/7 continuous automated |
| Ownership | Specific employee | Ambiguous (team/app-owned) |
| Volume | 1x baseline | 45x |
| Deprovisioning | Automatic | Manual, often forgotten |
Key Operational Differences
Lifecycle management is driven by a much different set of triggers. Human identities will follow the normal rules of employment, where HR systems such as Workday or SAP SuccessFactors will initiate provisioning once a new employee is hired and deprovisioning once they exit the company. NHI lifecycles will almost always be tied to technical events, such as deploying applications, provisioning infrastructure, or configuring services. The primary gap occurs when applications are truly retired or services are deprecated; no system automatically removes the users' credentials, leading to orphaned accounts indefinitely.
Authentication models are active rather than an interactive event. In the case of human identities, users will be prompted to log in, approve MFA notifications, biometrics, etc. NHIs will simply leverage manufactured and dormant/embedded authentication mechanisms. API keys are developed and embedded into the HTTP request header, service accounts will operate against Kerberos tickets or NTLM authentication mechanisms, code and/or certificates will prove identity through public-key cryptography, and OAuth flows use client credentials and access tokens without any users physically present to approve the transaction.
Access patterns demonstrate remarkably different behaviours. Human users will typically access systems during business hours from locations they can identify with labour-like activity patterns and predictable access. Automated processes, or service accounts, are typically active continuously and can authenticate thousands of times per hour from multiple server endpoints at the same time. This continuous activity 24/7 makes automated machine anomaly detection extremely difficult because what is an indicator of a compromised human account (a late-night access or a high rate of authentication) is normal behaviour for automated processes.
According to the IBM 2024 Cost of a Data Breach Report, breaches resulting from compromised credentials typically take about 250 days to identify. The detection of a compromise of machine credentials typically takes longer to identify due to the baseline of user behaviour being poorly understood, and security teams usually do not have visibility or understanding of what is classified as "normal" for machine activity.
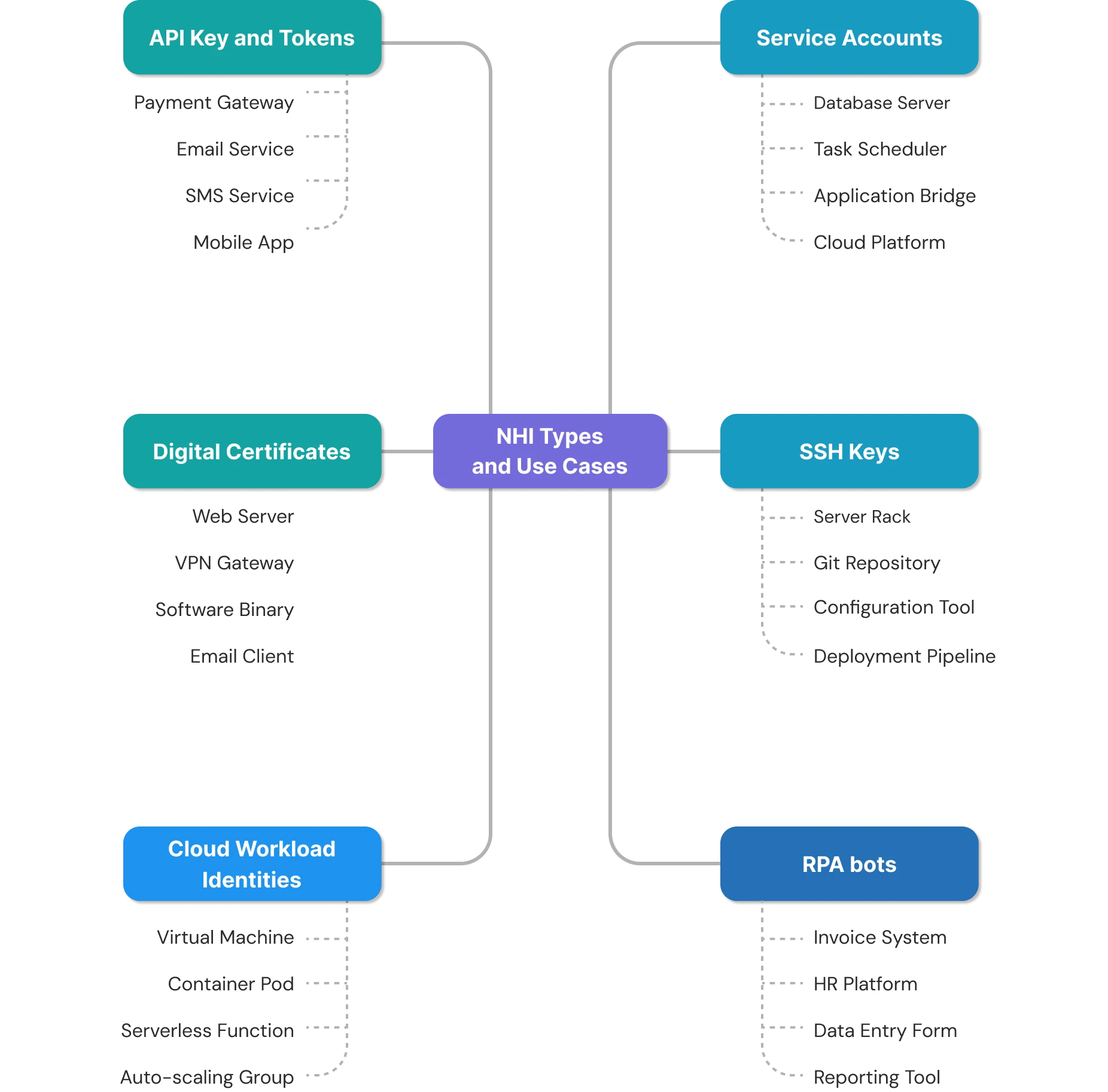
Types of Non-Human Identities
Service Accounts
- Service accounts are accounts with privileges that are created to be used to run applications and services instead of for individual users. On Windows, applications run under predefined accounts like
NT AUTHORITY\SYSTEMor user-defined accounts likeDOMAIN\svc_payroll. On Unix/Linux, daemon processes run under accounts like postgres (database), jenkins (CI/CD), or www-data (web server). These accounts automatically authenticate when the service starts and have the technical permissions the application requires. - The biggest challenge is permission accumulation. A service account that originally only needed read access to the database may have received write permissions as part of troubleshooting, but it is rare for those permissions to be revoked. In the cloud, this problem has extended well beyond the operating system with Azure Service Principals, AWS IAM Roles, or Google Cloud Service Accounts, which share the same processes by providing temporary credentialing automatically instead of a static password.
API Keys and Tokens
- API keys are proprietary identifiers that applications include in requests to authenticate themselves when making requests to external services. When your organization signs up for a service, such as Stripe, which is an online payment processor, or Twilio, which is an SMS platform, that service provides your application with an API key to include in each request. If any person has your API key, they can impersonate your application and gain access to your data.
- OAuth tokens offer a much safer, time-limited access token (generally an hour or less) for your application instead of a long-term key. Organizations should track usage of API keys continuously, rotate keys automatically every 90 days to manage API keys securely, and apply the least privilege security principle.
Digital Certificates
- Digital certificates leverage PKI to verify identity and secure communications. TLS/SSL certificates secure web traffic by proving identity and encrypting data on the server side. Client certificates are used to authenticate applications in mutual TLS, where both the client and server provide a certificate for authentication before exchanging any messages. Code signing certificates verify whether software or applications have been tampered with.
- The operational conundrum is lifecycle management. Most modern certificates expire after a maximum of 90 days, which means that they'll either need to be manually – or automatically–replaced at or before that expiration to avoid interruptions in service availability. Indeed, organizations will need to track these expiration windows against deployments that can number in the thousands. Expired certificates have already caused outages for many large companies, including Microsoft Teams and LinkedIn.
SSH Keys
- SSH keys enable authentication on servers without a password using public-private key pairs. The server keeps the public key, while the client proves ownership of a private key without sending it over the wire. DevOps workflows utilize SSH keys to automate tasks, such as connecting Ansible to hundreds of server clusters via SSH. Developers use SSH keys for Git authentication.
- The security issue is that keys can last forever. Unlike passwords, which have an expiration date, SSH keys do not. For example, a developer created an SSH key to enter a production server 5 years ago. The developer left the company 3 years ago, but the key still works. The organization may run into a situation where there are 50 or more public keys on a server, and there is no documentation of which key is still needed.
Cloud Workload Identities
- Cloud workload identities are credentials assigned automatically to compute resources available on cloud platforms, eliminating the need for stored passwords. For example, AWS IAM instance profiles apply to EC2 instances. Applications fetch temporary credentials from an instance metadata service, which are available only from that instance and rotate every few (e.g., every 2 or 6) hours. Azure Managed Identities, Google Cloud Service Accounts, and Kubernetes Service Accounts work similarly.
- With no stored credentials, we are left with no credentials to leak, via configuration files or via code repositories. The security challenge becomes managing the actual permissions. Organizations must ensure that workload identities remain least privileged, meaning that applications get only the specific permissions they need, versus blanket administrative permissions.
RPA Bots
- RPA (Robotic Process Automation) bots serve to automate business functions by interacting with applications via the end-user experience in the user interface, instead of through APIs. Tools like UiPath or Automation Anywhere, for example, allow a bot to log into applications, click buttons, navigate menus, and enter data just like a human. For example, an RPA bot that automates the process of processing invoices may log into email to download an invoice, look up vendor information, use the company's ERP system to check on purchase orders, and update the tracking spreadsheet.
- The catch is that bots need user-equivalent credentials, meaning the bots need an account with equal access to the system as the human employee. Bots also generally bypass MFA, as they cannot approve a push notification or scan a fingerprint. As a result, organizations need to exempt bot accounts from MFA, making the username and password the only form of authentication. If they are compromised, hackers get to use all of the same access to applications and sensitive data as an employee.
Why NHIs Matter in Cloud-Native Workflows
Cloud applications depend on non-human identities for automation that human credentials cannot provide.
- Service accounts are used by CI/CD pipelines to authenticate with source control, API tokens are used to push container images into registries, and SSH keys are used to deploy code to production servers. Each code commit triggers automated builds, tests, and deployments without the need for a human being to enter a password. Automation allows organizations to do multiple deployments every day, instead of manual releases once a month.
- Microservices architectures require continuous machine-to-machine authentication. For example, in an e-commerce application, the order service would authenticate to the inventory service to check stock, the payment service would authenticate to use API keys to process transactions with the external payment processors, and the notification service would connect to the email platform's API using OAuth tokens. Each interaction requires the calling service to authenticate its identity via certificates, tokens, or service accounts. According to the CNCF 2024 Annual Survey, organizations are now running an average of 2,341 containers, and each container must be able to authenticate its identity in order to securely perform its task.
- AI and automation systems operate autonomously without direct human representation. For example, AI-powered customer service agents can make decisions about real-time order status using service accounts to authenticate to CRM systems and using tokens to call external APIs. The same AI-powered agents can also invoke back-end workflows to escalate issues whenever required, and they are making decisions and taking actions based on programmatic logic, and don't require human approval to initiate each step.
- Cloud platform integration is entirely dependent on workload identities. AWS IAM roles can be assigned to Lambda functions to allow them access to S3 storage with no hardcoded credentials in code. Azure Managed Identities can be used by applications to log in to databases automatically. Kubernetes service accounts grant pods the ability to call the API of the cluster with permission. These cloud-native identity constructs eliminate the requirement for applications or workloads to store credentials by injecting them as temporary credentials at the time/point of use.
- Container orchestration greatly amplifies identity requirements. Sysdig's 2024 Cloud-Native Security Report, which examines millions of containers, discovered that 70% of containers have lifetimes under 5 minutes. When the traffic spikes, clusters scale from baseline to 20-50x capacity in a matter of minutes through autoscaling. Each new pod instance needs an identity immediately, including provisioning a service account token, associating IAM roles, and issuing certificate(s). Traditional identity management, built to handle relatively stable service accounts, will not work at this velocity, and this is the velocity at which pods are created and destroyed hundreds of times an hour.
- For Identity Confluence customers, Identity Confluence discovers and governs non-human identities, in addition to human identities. And, when applications deploy, automated workflows marry into CI/CD pipelines to provision service accounts. Policy engines check workload permissions against actual usage patterns. And as applications are decommissioned, lifecycle management discovers orphaned credentials, delivering complete governance at cloud-native scale.
Real-World Examples of Non-Human Identities
API Keys & Tokens
- API keys are distinct identifiers that are sent in requests to external services or APIs that confirm your application identity. You can think of API keys as passwords for software rather than human beings.
- When your organization registers with a third-party service, that service provides an API key (a long random string) that your application stores. When your application makes the request, it includes your key in the HTTP header. The service then checks that API key to verify your application's identity before proceeding with the request.
- Here is an example that is common for e-commerce applications: When you process payments, your application passes your Stripe API key along with the payment request to Stripe, the online payment processing platform that you use. When your marketing platform sends an email through SendGrid or a text through Twilio, it authenticates using the same API keys.
- API keys enable programs to communicate securely and automate the process without requiring human intervention to log in each time the program requires permission or recognition to communicate with the external service.
- Another authentication mechanism that builds on this concept is using OAuth tokens. OAuth tokens are secure 'bearer tokens' that provide your application with a short-lived access token for communicating with the external authentication service. Typically, these access tokens expire after one hour to limit damage if compromised.
- According to GitGuardian's 2024 State of Secrets Sprawl report, over 10 million secrets are exposed in public code repositories annually. Once exposed, anyone possessing your API key can impersonate your application until the key is revoked.
Service Accounts
- Service accounts are privileged accounts in directory systems created specifically to run applications and services rather than for individual users.
- In Windows, applications run as services under accounts like
NT AUTHORITY\SYSTEMor custom accounts likeDOMAIN\svc_payroll. In Unix/Linux, daemon processes run under dedicated accounts likepostgres(database),jenkins(CI/CD), orwww-data(web server). These accounts authenticate automatically when services start and hold the technical permissions applications need to function. - Your order processing application uses a service account to connect to the inventory database. This account authenticates automatically when the application starts, queries product availability, and updates stock levels without any human intervention.
- Service accounts enable applications to operate autonomously 24/7, accessing databases, file systems, and other resources needed for business operations.
- According to CyberArk research, 42% of service accounts have administrative privileges, and 68% of organizations cannot accurately inventory their service accounts. Over-permissioned accounts that accumulate permissions over the years represent high-value targets if compromised.
Certificates & SSH Keys
- Digital certificates leverage cryptography to validate identities and create encrypted communications. SSH keys allow for login to servers without requiring a password.
- TLS/SSL certificates consist of a public key and identity details, digitally signed by a third-party trusted authority, that allow the client to confirm the server is who it claims to be, and allow for encrypted communication to take place. When your browser connects to a website, the server presents its certificate in order to establish its authenticity and encrypted communication. SSH keys work by using public-private key pairs. The server keeps the public key, and the client possesses the private key without ever transmitting it.
- Every HTTPS website uses TLS certificates to protect the traffic. Your DevOps team uses SSH keys to roll out code changes to production servers, often with tools like Ansible, authenticating to hundreds of servers at once using SSH keys and not passwords.
- Certifications work to encrypt sensitive data in transit and provide server authentication to prevent man-in-the-middle attacks. SSH keys allow secure and automated server management at scale without the stress of stored plaintext passwords to manage.
- Certificates expire (modern certificates expire after 90 days), and if they are not replaced in time, services will go down while they are renewed. SSH keys often have no expiration dates, and they can be used years later by former employees to access your production servers, the reason being organizations do not have a method to systematically remove them.
Cloud Workload Identities
Cloud workload identities refer to the credentials automatically assigned to compute resources – like virtual machines, containers, and serverless functions – by cloud platforms on behalf of the user. The benefit is that the user does not need to store a password (or the cloud provider is not storing the password).
- For example, instead of storing AWS credentials within config files, you would assign an IAM role to your EC2 instance for the applications running on the instance to request temporary credentials from the EC2 instance metadata service. The process works by AWS providing the temporary credentials to applications running on the EC2 instance and automatically rotating the credentials every few hours. The temporary credentials would work from the instance and not if called from another instance or application.
- To illustrate, let's say you have a web application running on EC2 that needs to store user uploads to S3. Instead of hard-coding the AWS access keys, you would assign an IAM role to the EC2 instance that provides S3 permissions. The application will automatically obtain temporary credentials and upload files to S3 securely based on the temporary credentials using the EC2 instance role permissions. Azure Managed Identities, Google Cloud Service Accounts, and Kubernetes Service Accounts work similarly.
- If there are no stored credentials to begin with, there is nothing to leak in configuration files, code repos, or container images. The credentials are temporary, work with only authorized compute resources, and rotate automatically.
- While workload identities accomplish the goal of not having stored credentials, workload identities can still be over-permissioned. One of the common patterns for organizations is to create wide roles while developing for expediency, then forget to right-size the permissions after moving the application to prod..
Bots & RPA Processes
- RPA (Robotic Process Automation) bots are software programs that perform business tasks by interacting with applications in the same way that a human would use the application software's user interface, rather than via an API.
- RPA tools log in to applications, click buttons, navigate menus, fill out forms, and extract data just like an employee would. A bot that processes invoices might log into your email to download invoices, extract vendor information from the document, log into your ERP system to verify purchase orders, enter the invoice data, and update a tracking spreadsheet.
- A healthcare organisation uses RPA bots to extract patient data from referral documents and enter it into electronic health records. A finance organization uses bots to process accounts payable, reducing the time required for processing from days to hours while eliminating errors from human data entry.
- RPA is also applicable for automating legacy applications that do not have APIs available for integration. Furthermore, business users can build an automation workflow using low code that does not require traditional programming experience and drive digital transformation faster than traditional programming.
- Bots need user-equivalent credentials to interface with applications, often with the same access levels as human employees. Typically, bot accounts are excluded from MFA because they may not approve push notifications, which means that username and password become the only authentication factor. If the bot account is compromised, the attacker assumes employee-level access to business applications and sensitive data.
Top Security Risks of Non-Human Identities
Organizations implemented automation faster than they developed governance capabilities. According to Gartner, machine identities now outnumber human identities 45:1 in typical cloud environments. Despite this dramatic imbalance, most identity governance budgets focus almost exclusively on user accounts, creating a critical blind spot where the vast majority of digital identities receive minimal oversight.
Risk 1 - Over-Privileged Accounts
- Over-permissioning occurs when service accounts are assigned more permissions than what is needed. Development teams request access to the database, and administrators provide full database owner permissions instead of limiting it to the table for troubleshooting: the service deploys, and teams never look at those permissions again. Five years later, the service account now has database owner permissions and file system permissions, and is a member of administrative groups that are never removed.
- According to CyberArk, 42% of service accounts have administrative privileges. Datadog reports 78% of cloud IAM roles have unused permissions. Mitigation requires permission usage analysis using tools like AWS IAM Access Analyzer to identify permissions granted but never used. Policy-based provisioning prevents over-permissioning by mapping applications to predefined permission templates. Regular access certification prompts owners to review and justify permissions.
Risk 2 - Hardcoded Secrets & Credential Exposure
- Developers embed credentials directly in source code, configuration files, or container images because it's the fastest way to make code work during development. These hardcoded secrets then move from development into production systems. Credentials in Git repositories persist in version history even after deletion. Passwords in
.envfiles propagate across environments. Dockerfile credentials exist in image layers. Application logs capture connection strings. - According to GitGuardian, over 10 million secrets are exposed in public repositories annually. IBM reports 19% of breaches involve compromised credentials. Organizations need secrets management vaults like HashiCorp Vault, AWS Secrets Manager, or Azure Key Vault, where applications retrieve credentials at runtime instead of storing them. Pre-commit scanning tools like git-secrets scan commits for credentials and reject any containing secrets before they reach repositories.
Risk 3 - Lifecycle Management Gaps
- Machine identities lack the natural lifecycle triggers that human identities have. When employees leave, HR systems automatically disable their accounts. When applications are decommissioned, nobody remembers to remove the associated service accounts, API keys, and SSH keys. These orphaned credentials persist indefinitely with full permissions despite serving no purpose.
- According to CyberArk, 68% of organizations cannot accurately inventory their service accounts. Monitoring tools designed for 10,000 human users struggle with 450,000 machine identities. SOCs monitor human users but view service accounts as "just infrastructure" without clear ownership. Mitigation requires automated discovery, continuously identifying service accounts across infrastructure, ownership assignment linking every credential to responsible teams, and lifecycle integration that provisions credentials when applications deploy and deprovisions them when applications retire.
Risk 4 - Shadow Identities in DevOps
"Shadow identities" refers to credentials that developers generate outside any formal governance processes. DevOps emphasizes speed and autonomy, so when developers require credentials, they directly generate them via cloud consoles or CI/CD tools rather than through any approval workflow. For example, if a developer needs an S3 bucket, they log into AWS, create an IAM role, and are done within 15 minutes. This credential now exists in production, while the security teams are unaware that it exists at all.
- These shadow credentials create permission drift (development teams grant permissions that seem necessary, but without any security review), orphaned accounts (no one remembers these accounts years later), "no rotation" (there's no tracking of these accounts, so there's no concept of a rotation schedule), and potential compliance violations (if you do not keep track of access, you cannot demonstrate compliance with SOX requirements; in other words, you cannot document who has access).
- To mitigate this situation, you must have a discovery process that extends to the cloud provider's APIs that identify any IAM roles that are created through any of the consoles, any self-service portal that allows for the same type of functionality to request access, any self-service portal allowing for the same types of features or changing them through a self-service portal, as well as CI/CD integrations that require credentials to come from a vault versus being stored directly within the pipeline, in which case, you may or may not have tracking of the access being granted.
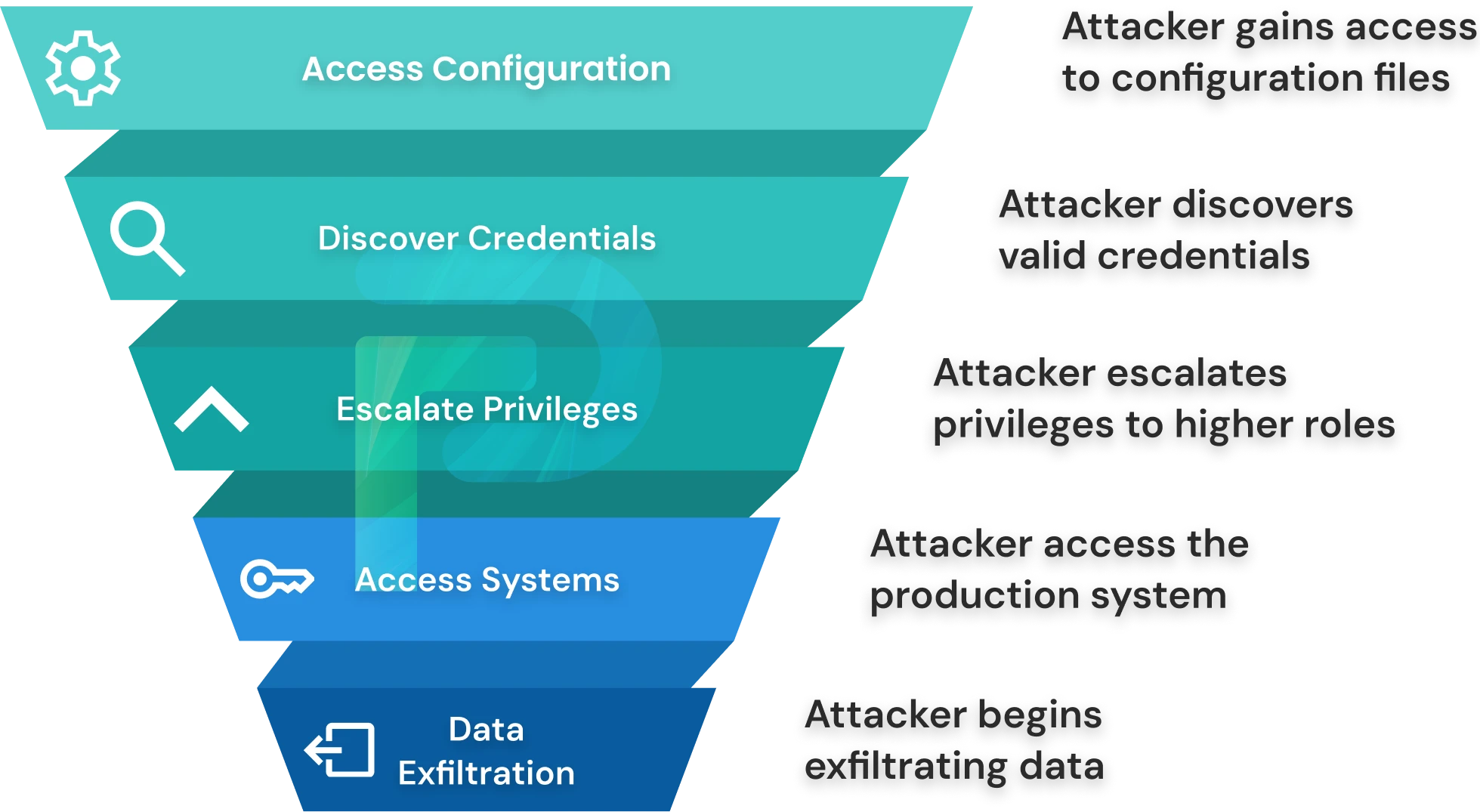
Best Practices for Securing Non-Human Identities
Practice 1 - Complete Inventory & Discovery
Identity inventory is the systematic cataloguing of all non-human identities across the infrastructure, labelling characteristics and maintaining catalogues as continuously updated sources of truth. If you cannot see an identity, you cannot govern it.
- Traditional inventories are based on Active Directory or LDAP user accounts. Non-human identities lack centralization and exist as Unix accounts, database accounts, application stores, cloud IAM, Kubernetes clusters, API registrations, certificate stores and SSH key files.
- Automated discovery platforms can discover identities, using integration adapters that connect to Active Directory via LDAP, AWS via boto3 SDK, Azure via Microsoft Graph API, Google Cloud via Cloud Asset API or Kubernetes clusters via other cluster APIs. Scaling discovery is important because you cannot manually catalogue 450,000 machine identities.
- Identity classification allows for service account governance, API key governance, certificate governance, etc. Documentation of what permissions each identity has is important to capture what each identity can do. Identity ownership is important to link ownership and responsibilities to identities. Promising to maintain continuous while detection automatically through scheduled scans (hourly/daily) that capture new identities. Event-driven updates allow for almost real-time accuracy because they subscribe to stream events coming from the cloud provider.
Practice 2 - Enforce Least Privilege Access
- The principle of least privilege states that identities should be assigned the least amount of permissions actually needed. Troubleshooting friction encourages and provides an incentive for over-permissioning, as error analysis can take hours, while granting admin rights immediately eliminates any errors present. Adding to the complexity of least privilege implementation is the permissioning of cloud services, with AWS IAM providing more than 10,000 permissions across 300 unique services.
- Implementation needs the analysis of any use of permission. Cloud access analyzers provide the capability to see what IAM actions were actually attempted. Database schemes may allow audit logs to capture the actual SQL statements. Policy-based provisioning can map application archetypes to predefined permission sets. Just-in-time access allows for elevated permissions for a temporary time, rather than a permanent time. Lastly, the separation of duties needs to be implemented in order to prevent the same identity from completing sensitive operations on their own if compromised.
Practice 3 - Automated Credential Rotation
- Credential rotation systematically replaces credentials on regular schedules, limiting the lifespan during which any credential remains valid. According to IBM, average breach identification takes 204 days with an additional 73 days to contain (a total of 277 days). Automated rotation policies ensure credentials discovered during investigations are likely already invalid.
- Implementation must include secrets management integration. Passwords for applications are retrieved from vaults at runtime instead of configuration files. The rotation workflows create new passwords and update and/or create databases to accept either the old passwords or the new passwords, update the vaults, signal the application to refresh credentials in memory, and remove old passwords after validation periods. The certificate lifecycle automation monitors validity periods and automatically renews certificates before expiration. The API key rotation enforces maximum lifespans using an automated workflow. SSH key rotation requires users to generate new SSH keys on a recurring schedule with automation to update files across a fleet of servers.
Practice 4 - Centralized Secrets Management
- Secure vaults serve as centralized, safe storage for credentials, in addition to providing encrypted storage, access controls, audit logging, and dynamic secret generation. Applications have traditionally stored credentials in source code, config files, or environment variables. Centralized vaults change the model where the credentials are stored in a single secure location, and applications access those credentials at runtime.
- Vault features include encryption at rest and during transit, access control policies that specify which applications are allowed to retrieve which secrets, audit logging that captures when and what secrets are accessed, dynamic secret generation to avoid storing static credentials, and secret versioning that retains version history of credential changes.
- The implementation workflow follows a series of steps that can include migrating secrets from a previous store by systematically discovering all the secrets within an application, loading the vault with secrets following a structured hierarchy and policy path, refactoring the application code, updating the application code to access secrets from the vault, verifying that the migration process was successful, and revoking secrets by removing secrets from the previous store.
Practice 5 - Continuous Monitoring & Anomaly Detection
- Anomaly detection with non-human identities consists of establishing behavioural baselines to define normal authentication and activity behaviour and then looking for indications that those credentials have been compromised (through deviations from the baseline).
- To establish baselines, it is necessary to capture authentication behaviours (i.e., frequency, timing, and source of authentication), access behaviours (i.e., what resources were accessed), and privileged behaviours (i.e., how the permission granted was utilized). Machine learning algorithms take authentication log data over the baseline period of 90 days and establish statistical models.
- Behavioural anomaly detection identifies anomalies based on actor time, source of authentication, access of resources, privilege escalation behaviour (attempts to leverage more than the permissions assigned), and data exfiltration behaviour (movement of data outside of expected behaviour).
- Monitored behaviour must also be coordinated with a response. This requires the automated routing of alerts, directing deviations to the appropriate teams; alerts with context that help fuel the investigative basis; and automated response capabilities through suspending credentials, forcing credential rotation, and restricting access.
Practice 6 - Apply Zero Trust Principles
- Zero Trust is a security framework that assumes breach and verifies every access request, regardless of source. Traditional network security relied on perimeter-based trust. Zero Trust is the opposite of network-based trust, where every access request is verified.
- The Zero Trust principles for NHI include verifying explicitly (every authentication has to be verified against a predefined policy), least privilege access (grants only minimum required permissions), and assuming breach (control is designed to expect an attacker will compromise some credentials).
- Implementing Zero Trust involves requiring mutual authentication (both entities to be verified through mutual TLS), continuous authentication (replacing the concept of a one-time authentication with ongoing verification), policy enforcement points (evaluating an access request against an established policy before granting access), risk-based authentication (allowing an analyst to evaluate permissions based on a dynamic risk assessment), and microsegmentation (to contain or limit lateral movement through network based controls)this can include processes as well.
What is Non-Human Identity Management (NHIM)?
Identity management for non-human entities is an extension of identity governance and administration for human users to machine credentials. It provides identities as service accounts, API keys, certificates, and workload identities with the same systematic lifecycle management, policy enforcement, access certification, and auditing capabilities of identity management that has historically been applied to employee accounts.
Enterprises have worked for decades to establish and refine employee access governance with formal provisioning workflows, role-based access control, quarterly access reviews, and automated deprovisioning. Today, with approximately 450,000 machine identities compared to just 15,000 employees (the ratio is 30:1), it is hard to maintain informal management and governance of non-human identities.
How NHIM Differs from Traditional IAM
- IAM centres on overseeing human user identities via authentication methods for interactive login, user provision based on HR links, role-based access control that maps job roles to permission sets, access reviews with business managers, and deprovisioning associated with employee termination.
- NHIM centres on machine credentials via programmatic authentication (API keys, certificates, tokens), provisioning based on app deployment, policy-based access control with technical patterns indicating permissions, access reviews with the technical owner each time, and manual deprovisioning associated with application retirement. Lifecycle authority stems from DevOps tools instead of HRIS (CI/CD, IaC, orchestration).
NHIM's Role in Compliance
- Sarbanes-Oxley (SOX) mandates systems of internal controls for access to the financial systems. Additionally, there are segregation of duties requirements applicable to service accounts. Organizations must have documented policies surrounding SoD policies; identity governance platforms can evaluate service account permissions against these rules. Access certification verifies that service account permissions are routinely evaluated. Change management contemplates the organization documenting the reasons for changes in service account permissions and that there are records as to the approval of that change.
- HIPAA applies to covered entities and protected health information. Access controls mean adopting technical policies to limit access to ePHI through authorized software programmes. Unique user identification means a unique identifier is assigned to software accessing ePHI. Audit controls require documented actions reviewed and examined for sufficient detail.
- GDPR applies to organizations addressing personal data concerning EU residents. Security of processing means implementing appropriate technical measures. Data protection by design means that the principles of data protection are adopted during design. Accountability means demonstrating compliance with GDPR through documentation, access certification records, and audit logs.
Why IGA + NHIM Integration is Critical
- The traditional IGA markets were exclusively engaged with user lifecycle management. The convergence of IGA and NHIM provides unified identity governance via unified policy frameworks that apply uniform principles associated with every identity type, complete audit visibility that shows every identity that interacts with sensitive systems, lifecycle orchestration across identity types which enables application-centric governance, risk aggregation that provides complete identity risk visibility, and an enablement of Zero Trust that establishes a need for unified identity governance.
- Identity Confluence represents the maturing of the IGA + NHIM convergence and provides users with unified discovery, lifecycle automation, policy-based access control, access certification campaigns, identity analytics and compliance reports. Organizations no longer engage separate governance programmes for human and machine identities maintained through single platforms, unified processes, consistent policy application and visibility.
The Future of Non-Human Identity Security
Ensuring the security of non-human identities in the future requires machine credentials to be treated equally to human workforce accounts through integrated platforms, automated lifecycles, and contextual access controls. Organizations can no longer manage human identities and machine identities separately, as machine identities can outnumber humans 45 to 1. Having total visibility of all identities is key to success; applying the least privilege principle consistently and implementing Zero Trust principles across both types of identities is key to success.
Unified Platforms Replace Fragmented Tools
- Today, organizations manage human identities on IAM systems and machine identities using disparate solutions, such as certificate managers, secrets vaults, and cloud dashboards. This disconnect creates blind spots where credentials can live without any governance to protect or track them. In the future, one unified platform will offer a single source of truth for all identities, applying the same policies depending on whether the identity is a human employee, service account, API key, or container pod.
- The same governance will enable the opportunity for comprehensive risk detection across the entire identity landscape. When machine identities and identities live in separate systems, extending security teams' understanding of compromised employee accounts connected to the applicable service accounts, or what API keys came from real developers, is not possible. Bringing these identities under a unified governance approach permits correlation and robust dependency mapping, including complete audit trails.
Automation Becomes Mandatory, Not Optional
- Manual processes cannot scale to hundreds of thousands of machine identities that change constantly. According to Sysdig's 2024 report, 70% of containers live less than 5 minutes, creating identity lifecycles measured in minutes rather than months. Future solutions must automatically discover new identities as they're created, continuously monitor their behavior against baselines, and immediately flag anomalies or policy violations.
- Automated secrets management will become standard practice. Organizations need tools that automatically discover hardcoded credentials in source code, configuration files, and container images, then migrate them to centralized vaults without manual intervention. Automated rotation workflows will regularly replace credentials on schedules appropriate to risk levels, with high-privilege credentials rotating more frequently than low-risk ones.
Zero Trust Extends to Machine Identities
- The concepts of Zero Trust, which transformed human identity management, will extend broadly to machines. In the future, access decisions will be based not just on "what" credentials an identity possesses, but on "why", "when", "where", and "how" they are requesting access. Service accounts authenticating from outside expected networks, API keys accessing unusual amounts of data, or certificates being used outside routine time windows will result in dynamic actions ranging from increased logging to automatic suspension of credentials.
- Contextual and risk-based access will replace static permissions. Rather than being granted permanent access to a database, systems will assess access on each connection attempt: "Is this the application you were expecting?" "Is this during business hours?" "Does the volume match historical access?" "Has this identity demonstrated suspicious behaviour?" With real-time risk scoring, access may be granted normally, granted but highlighted for investigation, or modified to be simply read-only, or denied until further investigation occurs.
Ready to Secure Your Non-Human Identities?
With machine identities outnumbering human identities 45:1, organizations cannot afford governance blind spots. Identity Confluence provides comprehensive Identity Governance and Administration, extending proven IGA capabilities to machine credentials.
To learn how Identity Confluence can bring your non-human identities under control.
Frequently Asked Questions (FAQs)
1. What is a non-human identity?
A digital credential used by machines, applications, or automated services to authenticate without human involvement, including service accounts, API keys, certificates, and tokens.2. What are examples of non-human identities?
API keys for Stripe or Twilio, service accounts in Active Directory, OAuth tokens, TLS certificates, SSH keys, AWS IAM roles, Azure managed identities, and RPA bot credentials.3. Why are non-human identities important?
They enable automation and scalability modern IT requires but create security risks through over-permissioning, credential exposure, and lack of lifecycle management when ungoverned.4. How are non-human identities created?
Programmatically by developers through cloud consoles, API calls, Infrastructure-as-Code templates, or CI/CD pipelines during application development and deployment.5. What is non-human identity management?
Applying identity governance principles to machine credentials, including systematic discovery, lifecycle management, policy-based access control, regular reviews, credential rotation, and monitoring.6. What are the biggest risks?
Over-privileged accounts (42% have admin privileges per CyberArk), hardcoded secrets (10 million+ exposed annually per GitGuardian), lack of lifecycle management (68% can't inventory accounts per CyberArk), and insufficient monitoring.7. How often should credentials be rotated?
API keys every 90 days, service account passwords every 60-90 days, certificates 30-45 days before expiration, and non-SSH keys annually (or use certificate-based SSH with 8-24 hour validity).8. Can service accounts use multi-factor authentication?
Not traditional MFA, but organizations can implement equivalent controls through certificate-based authentication, mutual TLS, dynamic secrets from vaults, and context-aware authentication.9. How does Identity Confluence secure non-human identities?
Through automated discovery across hybrid infrastructure, lifecycle automation tied to application deployment, policy-based access control enforcing least privilege, access certification campaigns including NHIs, secrets management integration, identity analytics detecting anomalies, and compliance reporting for SOX, HIPAA, and GDPR.





Blogs You Might Like