



Kafka Chronicles: Navigating Common Challenges & Pitfalls in Event Schema Evolution





Abstract
In this article today, we’re exploring Kafka, an open-source distributed event streaming platform, mainly used for high-performance data pipelines, streaming analytics and data integration. At its core, Kafka operates on a publish-subscribe model, where the producer sends messages to Kafka topics, and the consumer subscribes to these topics to retrieve and process the messages or events. A key part of this process is serializing messages, turning them into a stream of bytes before sending them. When consumed, consumers deserialize the bytes back into the desired data type for processing.
Background and Problem Statement
Scenario
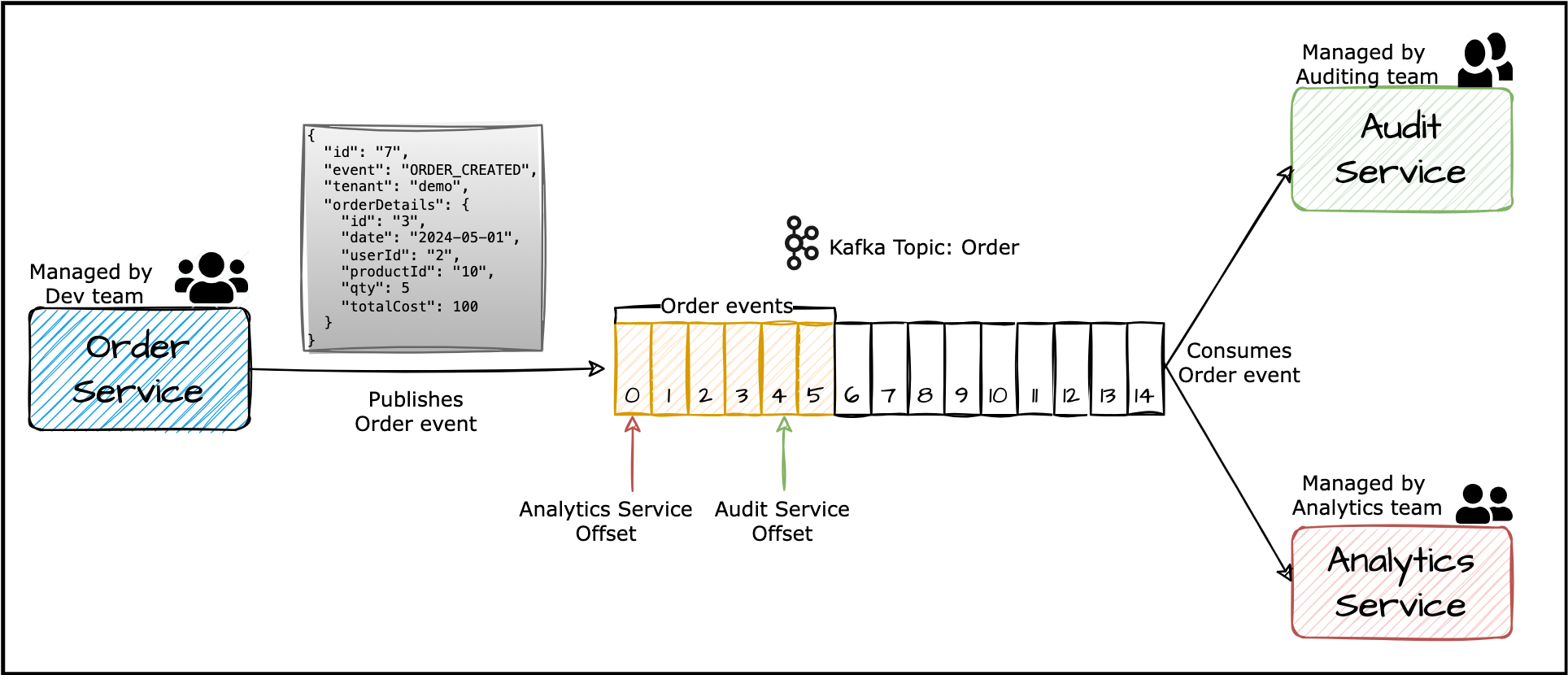
Imagine a scenario where we have these microservices:
- Order service, managed by the Dev team.
- Analytics service, managed by the Analytics team.
- Audit service, managed by the Auditing team.
When a user places an order, the Order service publishes an ORDER_CREATED event on the order topic. Both the Analytics and Audit services consume this event and then carry out the further processing.
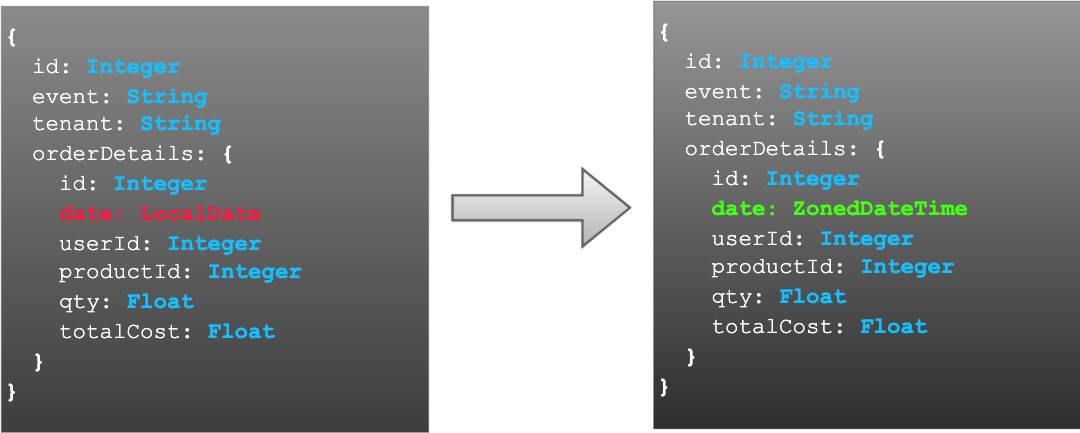
Now, suppose the Dev team needs to change the data type of the date present in orderDetails to include the time along with the date when the order was placed. Here’s the process they’ll follow:
- The Dev team updates the data type of the date field from LocalDate to ZonedDateTime.
- They communicate this exact change to the Analytics and Auditing teams.
- The Analytics and Auditing teams update their instances of the Order Event based on the specified changes.
- Once all three services have integrated the change, they coordinate and release simultaneously.
What do you think of this scenario and the process for updating the event’s schema? Sounds straightforward, right? But as with any system, there are potential pitfalls and challenges to watch out for.
Common Challenges and Pitfalls
-
Source of Truth
Firstly, let’s consider the declaration of the event. As shown in the image (iii), each service maintains its own copy of the Order event. The order service serializes the Order event, defined by class com.abc.order.OrderEvent into the stream of bytes and publish it to the Order topic. The analytics and audit service consumes this stream of bytes and deserializes it to the class
com.abc.analytics.OrderEventandcom.abc.audit.OrderEventrespectively.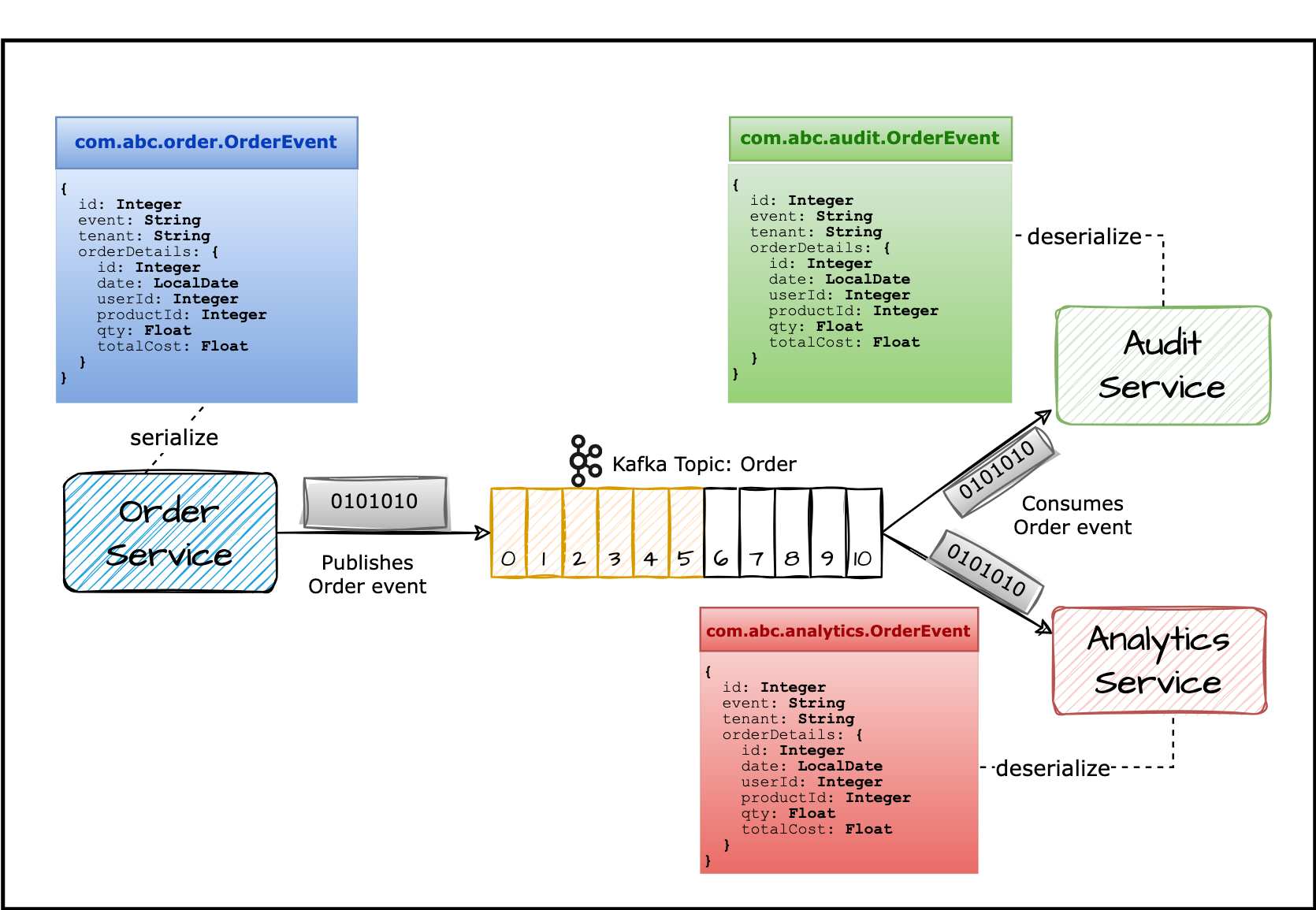
Each service declaring its own copy of the Order event Updates to the event structure or format require changes across all services, leading to duplication of effort and potential inconsistencies violating the DRY (Don’t Repeat Yourself) principle. Moreover, the lack of a single source of truth makes tracking the evolution of the Order event challenging, further complicating maintenance and updates.
-
Compatibility Concerns
What happens if the new event schema (let’s call it V2) isn’t compatible with the original schema (V1), and vice versa? Consider this, updating the data type of order date from LocalDate (V1) to ZonedDateTime (V2) is not backward compatible. This means the stream of bytes representing the V2 event cannot be deserialized back into the model representing the V1 event, and vice versa. Any V1 events still lingering in the Kafka topic, waiting to be consumed, become problematic. The updated Analytics and Audit services, expecting V2 events, won’t be able to consume these V1 events.
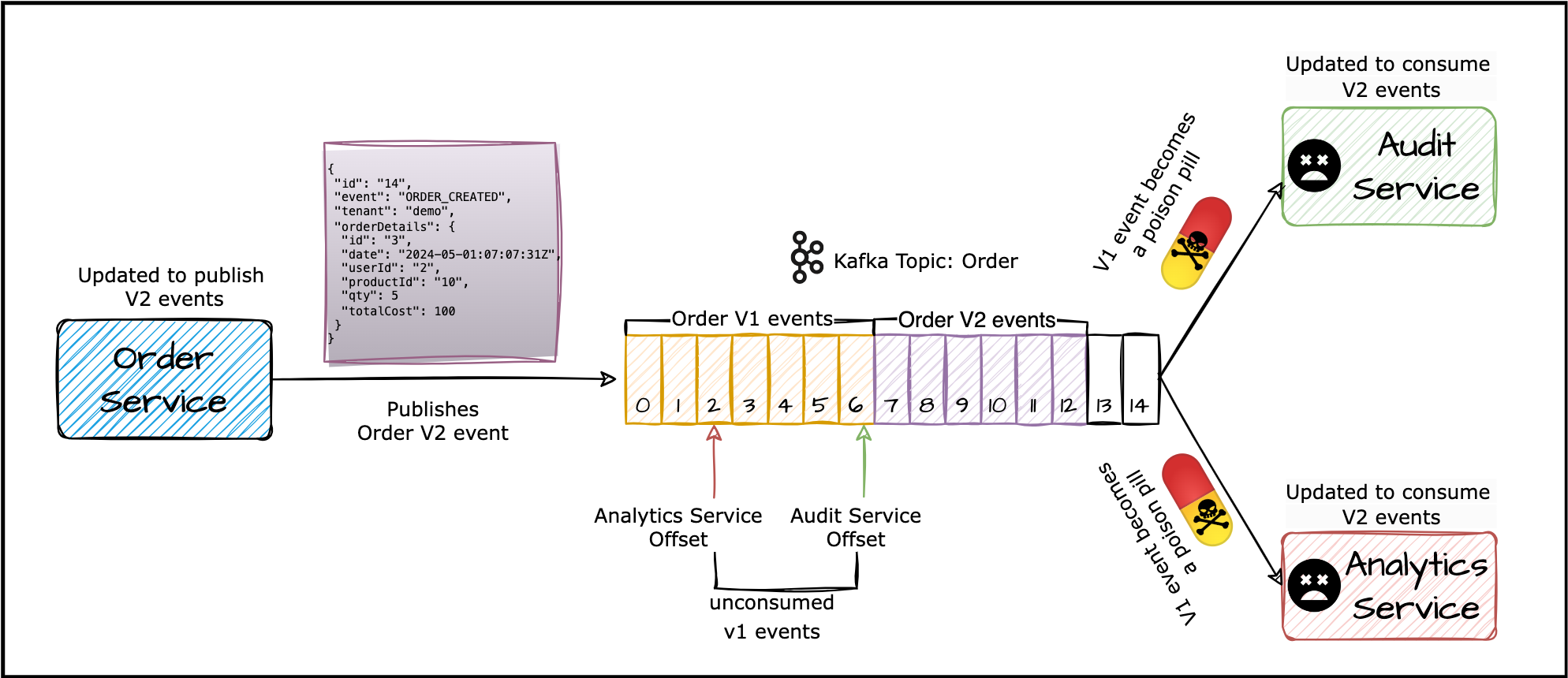
The V1 schema of the event is not compatible with the V2 schema of the event This mismatch will result in missed events, causing disruptions in data processing. Without proper error handling, these V1 messages essentially become poison pills, potentially terminating consumers prematurely and worsening the situation.
-
Synchronization of Releases
Another hurdle arises if the Auditing team can’t release the change simultaneously. Picture this: the Dev and Analytics teams forge ahead with the release, but the Auditing team lags behind due to other priorities. In this scenario, the Order service will start publishing V2 events. Since this change from V1 to V2 is not backward compatible, the Audit service won’t be able to deserialize the V2 events because it is still expecting V1 events.
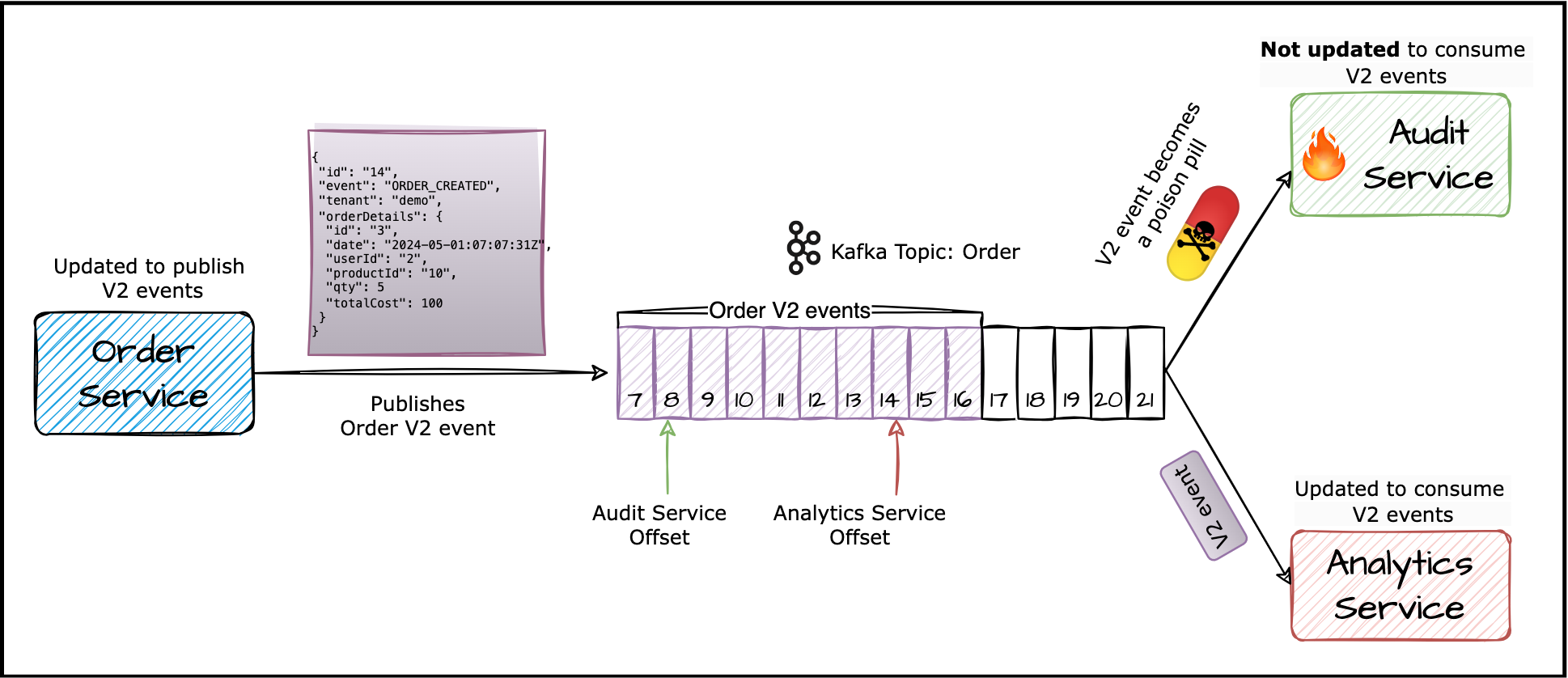
Audit service not updated to consume the V2 events As a result, the Audit service misses out on these events, leading to data inconsistencies. This delay highlights the tight coupling between the change in event schema and consumer services, emphasizing the need for synchronized releases to prevent disruptions and maintain system integrity.
Technology Used

Conclusion
As we delve into Kafka’s role in helping microservices communicate, we encounter unexpected hurdles. What seemed like a simple task of updating the event schema unveiled hidden complexities. We learned about compatibility issues with schema evolution, challenges with the synchronizing of releases, and the need for a single source of truth in declaring event models. To tackle these common challenges and steer clear of pitfalls, we need to find answers to these questions:
- How can we restrict teams from making breaking changes to the event structure?
- How can we ensure that poison pill messages are not published by the producer services to the Kafka topic?
- How can we decouple schema modification from the release of consumer services so that changes can be independently released without waiting on consumer services?
- How do we maintain a single source of truth for our schemas and adhere to the DRY principle?
In the upcoming part of the blog, we will explore various approaches to address these questions and overcome these obstacles.






Blogs You Might Like



